写这篇文章的起因是我一个朋友的女友发表博士论文中要对采集的数据进行分析拟合,刚好这段时间工作不忙,在研究Python,所以就去折腾折腾。下面是两个需求:
1
2
3
4
5
需求一:根据公式计算MVD、MDN
MND计算公式:[Σ(Bin Diameter*Num)]/Σnum
MVD计算公式:ΣVolum/Σnum=4/3*pi*r^3
计算结果写入Excel表中
需求二:通道合并及对数正态分布拟合(这个是什么我也不懂,反正就根据公式进行拟合吧)
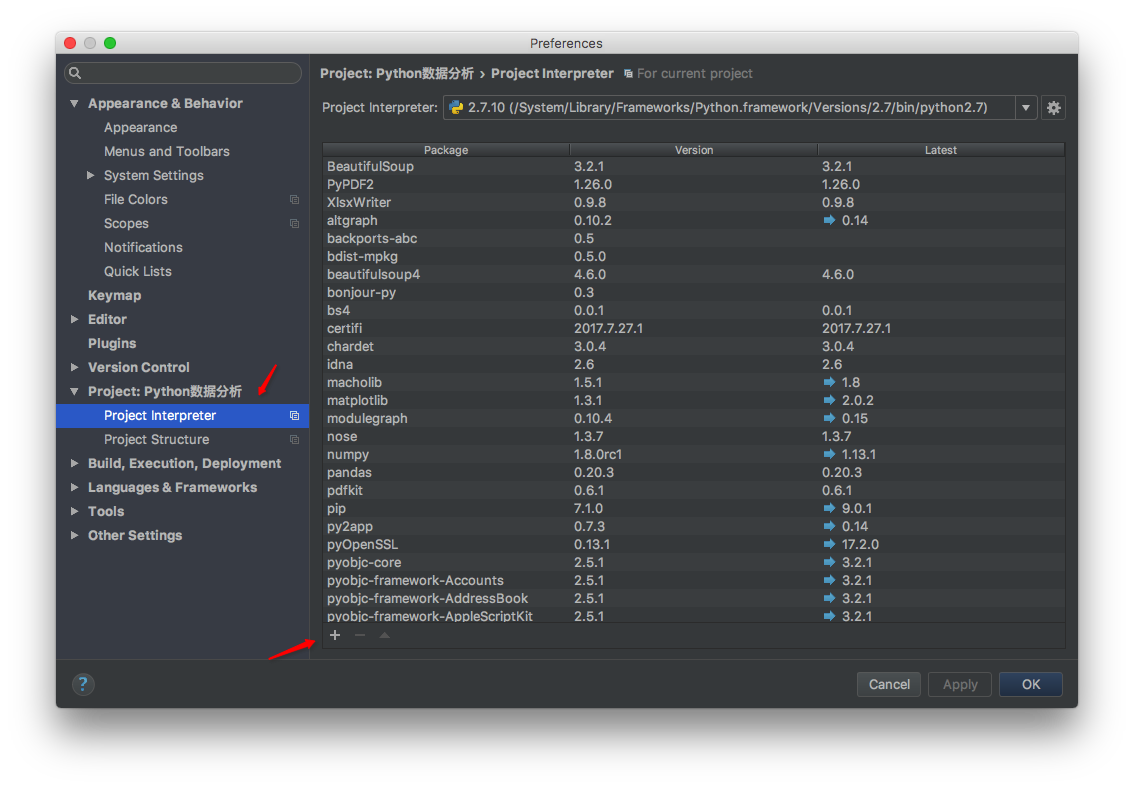
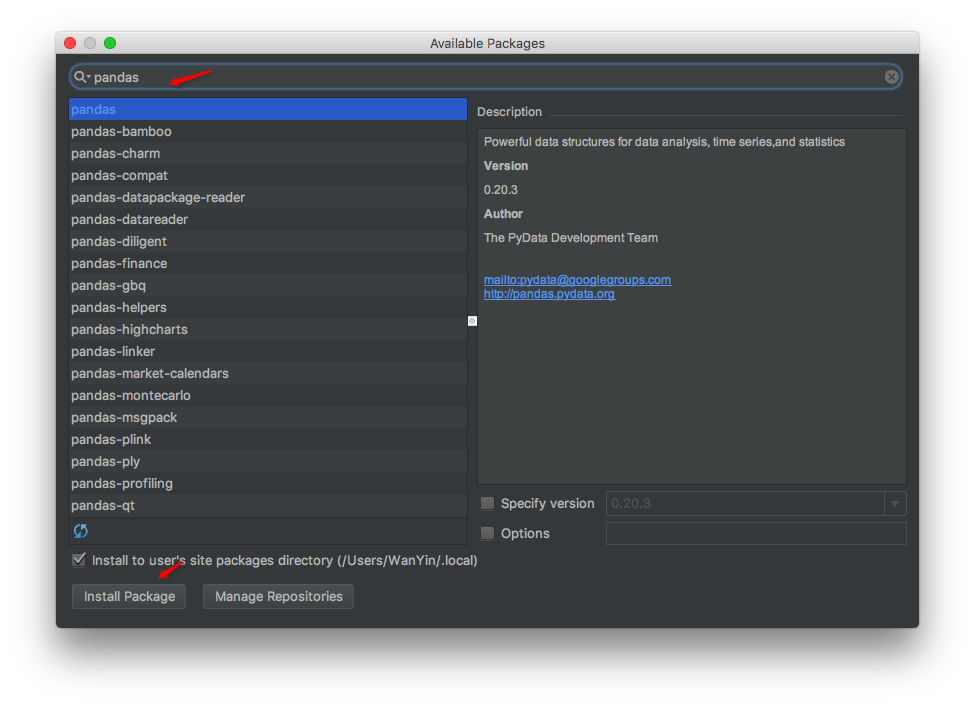
俗话说工欲善其事必先利其器,做事之前我们得找些高效的工具。这里我们选择Python中的结构化数据分析利器-Pandas,写入Excel时要用到xlsxwriter库,现在首先安装这两个库。我们打开PyCharm(很好用的Python解释器)点击PyCharm Community Edition -> Preferences首先点击右上角箭头下拉选择Python2.7然后再按图示箭头选择
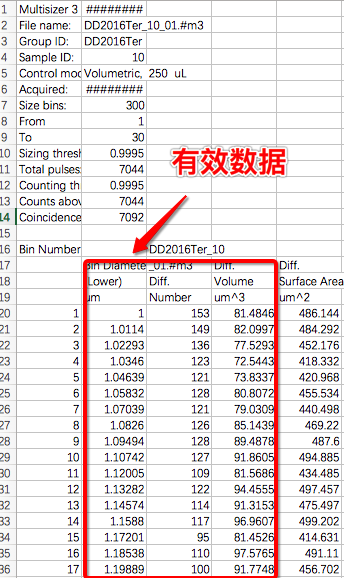
安装完成开始写代码,首先解决需求一,先看一下数据格式
要想分析数据我们得读取数据,我们的数据格式是.csv文件,首先我们用Pandas读取数据的格式为table = pd.read_csv(path,names=list('abcde'),na_values = ["um","(Lower)","Diff.","Volume","Number","um^3","um^2"])其中path为文件地址,names为读取出数据后每列的标识,因为我们的数据最多前五列有用,其他无用数据舍去,所以用abcde标识5列数据。这里要注意的是na_values参数,因为有7000个表,每个表中的数据格式有可能不一样,这里我们要过滤表中的"um","(Lower)","Diff.","Volume","Number","um^3","um^2"数据。运行程序看看读取的数据长什么样子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
a b c d \
0 Multisizer 3 2017-5-12 10:50 NaN NaN
1 File name: DD2016Ter_10_01.#m3 NaN NaN
2 Group ID: DD2016Ter NaN NaN
3 Sample ID: 10 NaN NaN
4 Control mode: Volumetric, 250 uL NaN NaN
5 Acquired: 2017-5-12 10:49 NaN NaN
6 Size bins: 300 NaN NaN
7 From 1 NaN NaN
8 To 30 NaN NaN
9 Sizing threshold: 0.9995 NaN NaN
10 Total pulses: 7044 NaN NaN
11 Counting threshold: 0.9995 NaN NaN
12 Counts above threshold: 7044 NaN NaN
13 Coincidence corrected: 7092 NaN NaN
14 NaN NaN NaN NaN
15 Bin Number NaN DD2016Ter_10 NaN
16 NaN Bin Diameter _01.#m3 NaN
17 NaN NaN NaN NaN
18 NaN NaN NaN NaN
19 1 1 153 81.4846
20 2 1.0114 149 82.0997
21 3 1.02293 136 77.5293
22 4 1.0346 123 72.5443
23 5 1.04639 121 73.8337
24 6 1.05832 128 80.8072
25 7 1.07039 121 79.0309
26 8 1.0826 126 85.1439
27 9 1.09494 128 89.4878
what‘s the fuck! 这是什么乱七八糟的东西,没办法源数据上面就是一大坨没用的描述,既然如此那我们在对数据进行裁剪一下吧这里要提到Pandas对数据切片语法了
1
2
3
4
5
6
7
8
9
10
11
#使用标签选取数据:
df.loc[行标签,列标签]
df.loc['a':'b']#选取ab两行数据
df.loc[:,'one']#选取one列的数据
#使用位置选取数据:
df.iloc[行位置,列位置]
df.iloc[1,1]#选取第二行,第二列的值,返回的为单个值
df.iloc[0,2],:]#选取第一行及第三行的数据
df.iloc[0:2,:]#选取第一行到第三行(不包含)的数据
df.iloc[:,1]#选取所有记录的第一列的值,返回的为一个Series
df.iloc[1,:]#选取第一行数据,返回的为一个Series
我们执行data = table.iloc[17:(len(table) - 1), 1:4]表示我们读取数据的第17行开始到表的倒数第一行,第二列到第第四列,看看切片后的数据:
1
2
3
4
5
6
7
8
9
10
b c d
17 NaN NaN NaN
18 NaN NaN NaN
19 1 153 81.4846
20 1.0114 149 82.0997
21 1.02293 136 77.5293
22 1.0346 123 72.5443
23 1.04639 121 73.8337
24 1.05832 128 80.8072
25 1.07039 121 79.0309
第17,18行没有有用的数据为什么不从19行开始读呢?这个就是因为她给的数据格式不统一!不统一!其他文件里17、18行是有可能有数据的。接下来我们要对缺失数据进行处理data = data.dropna(how='all')这句是去除全部是缺失数据的行,是全部,如果一行中只有一个缺失数据是不会被去除的,所以我们再加上一句data = data.fillna(0).astype(float)这句是用0替换掉表中的缺失数据,然后将数据全部转换为float格式,不转换是文本格式没法计算的。最后我们再给data起个别名,便于记忆data.columns = ['BinDiameter', 'Num', 'Volum']现在我们再看下数据
1
2
3
4
5
6
7
BinDiameter Num Volum
19 1.00000 153.0 81.4846
20 1.01140 149.0 82.0997
21 1.02293 136.0 77.5293
22 1.03460 123.0 72.5443
23 1.04639 121.0 73.8337
24 1.05832 128.0 80.8072
大功告成有木有!这数据是不是很赏心悦目呀!接下来我们终于可以计算MVD,MND了,喜大普奔😂
根据上面的公式我们定义两个方法分别求出MVD,MND
1
2
3
4
5
6
7
8
9
10
11
12
def mvd(data):
# 球体积=ΣVolum/Σnum=4/3*pi()*r^3反推出d大小
return ((data['Volum'].sum() / data['Num'].sum()) / ((4/3) * math.pi)) **(1.0/3)
def mnd(data):
# [Σ(Bin Diameter*Num)]/ΣNum
# Num列数据求和
Num = data['Num'].sum()
print("Num和为 %f" % (Num))
# Bin Diameter*Num
bn = data["BinDiameter"] * data["Num"]
print("BinDiameter*Num的和= %f" % (bn.sum()))
return (bn.sum() / Num)
解释:data['Volum'].sum()表示Volum列所有数据的求和。data["BinDiameter"] * data["Num"]表示BinDiameter列数据对应于Num列数据相乘,一一对应乘积的关系,得出一列数据bn,bn.sum() / data['Num'].sum()即MND,就是这么简单暴力的计算。
最后我们要将数据写入Excel中,再定义一个方法
1
2
3
4
5
def writerWithExcel(mnd,mvd,indexList):
df = pd.DataFrame({'MND': mnd, 'MVD': mvd},index=indexList)
writer = pd.ExcelWriter('simple.xlsx', engine='xlsxwriter')
df.to_excel(writer, sheet_name='Sheet1')
writer.save()
解释:拿到mnd,mvd的值我们先建立DataFrame对象df = pd.DataFrame({'MND': mnd, 'MVD': mvd},index=indexList)其中index表示每行的标识,这里我们要传入每个样本的名称,然后调用ExcelWriter传入文件名称写入Excel保存。
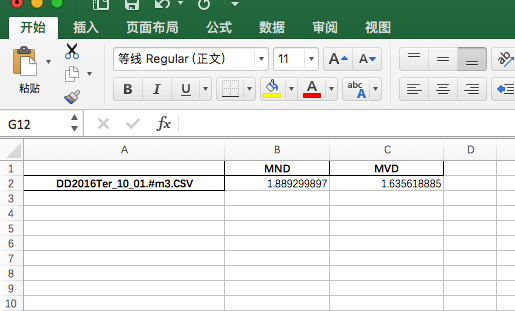
最后我们看下结果
单个文件处理完成,剩下的就是for循环处理7000个文件了,源代码
需求二
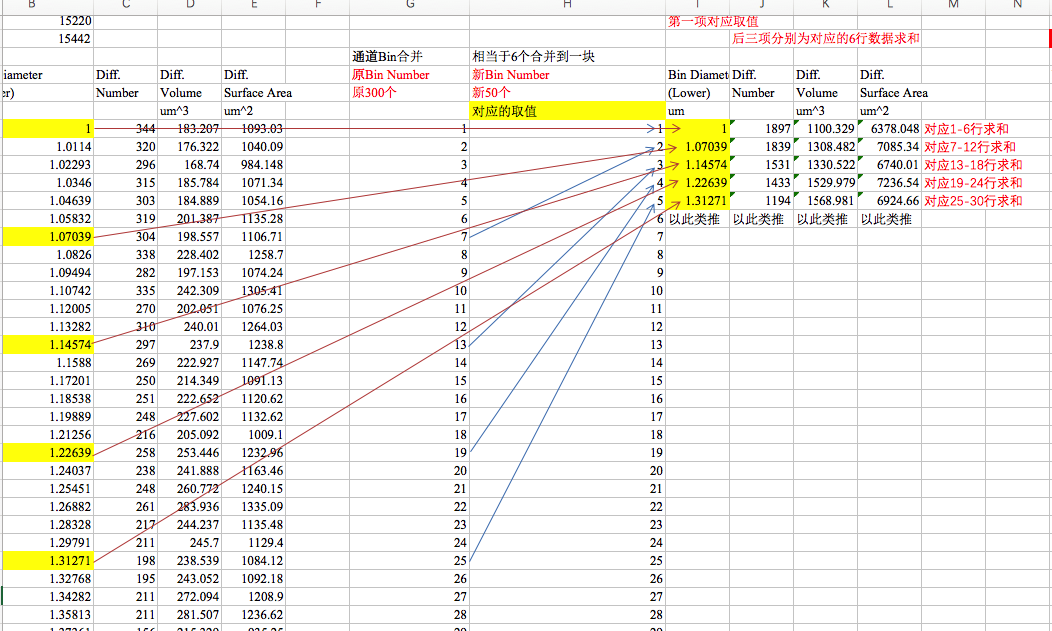
在需求一的处理好的数据基础上首先按要求进行通道合并
首先的按要求进行数据切片,按6行一组切片
1
2
3
4
5
6
7
8
9
10
11
12
#通道合并
def calculateWithPerSixRow(data):
# 获取第一行的行标签,即切片数据的起始行数
startIndex = data.index[0]
for x in range(len(data)):
if (x % 6 == 0):#对6进行取余
endIndex = (startIndex + 6) - 1
if endIndex > data.index[-1]:#如果最后一组的末尾行数超过了data的总行数,那此组数据舍去
pass
else:
print "分组数据为%d--------%d行" % (startIndex, endIndex)
startIndex = endIndex + 1
打印一下分组的起始行标识
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
分组数据为19--------24行
分组数据为25--------30行
分组数据为31--------36行
分组数据为37--------42行
分组数据为43--------48行
分组数据为49--------54行
分组数据为55--------60行
分组数据为61--------66行
分组数据为67--------72行
分组数据为73--------78行
分组数据为79--------84行
分组数据为85--------90行
分组数据为91--------96行
分组数据为97--------102行
分组数据为103--------108行
分组数据为109--------114行
分组数据为115--------120行
分组数据为121--------126行
分组数据为127--------132行
分组数据为133--------138行
分组数据为139--------144行
分组数据为145--------150行
分组数据为151--------156行
分组数据为157--------162行
分组数据为163--------168行
分组数据为169--------174行
分组数据为175--------180行
分组数据为181--------186行
分组数据为187--------192行
分组数据为193--------198行
分组数据为199--------204行
分组数据为205--------210行
分组数据为211--------216行
分组数据为217--------222行
分组数据为223--------228行
分组数据为229--------234行
分组数据为235--------240行
分组数据为241--------246行
分组数据为247--------252行
分组数据为253--------258行
分组数据为259--------264行
分组数据为265--------270行
分组数据为271--------276行
分组数据为277--------282行
分组数据为283--------288行
分组数据为289--------294行
分组数据为295--------300行
分组数据为301--------306行
分组数据为307--------312行
分组数据为313--------318行
接下来进行数据切片
1
2
3
4
#根据起始index取出对应startIndex到endIndex的行数的数据
tempData = data.loc[startIndex:endIndex]
#取出每组数据第一行的值tempData.values是一个二维数组
firstValue = tempData.values[0][0]
我们来看一下tempData.values的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
分组数据为19--------24行
[[ 1. 153. 81.4846 ]
[ 1.0114 149. 82.0997 ]
[ 1.02293 136. 77.5293 ]
[ 1.0346 123. 72.5443 ]
[ 1.04639 121. 73.8337 ]
[ 1.05832 128. 80.8072 ]]
分组数据为25--------30行
[[ 1.07039 121. 79.0309 ]
[ 1.0826 126. 85.1439 ]
[ 1.09494 128. 89.4878 ]
[ 1.10742 127. 91.8605 ]
[ 1.12005 109. 81.5686 ]
[ 1.13282 122. 94.4555 ]]
接下来我们把每组数据的值进行计算后存入数组中
1
2
3
newBD.append(firstValue)#每组数据第一行的值
newNum.append(tempData['Num'].sum())#每组数据Num列的求和
newVolume.append(tempData['Volum'].sum())#每组数据Volum列的求和
最后我们再次构造一个DataFrame对象df = pd.DataFrame({'BD': newBD, 'NMU': newNum, 'VOL': newVolume})打印一下看看结果是不是预期的值
1
2
3
4
5
6
7
8
9
10
11
BD NMU VOL
0 1.00000 810.0 468.2988
1 1.07039 733.0 521.5472
2 1.14574 629.0 547.3834
3 1.22639 553.0 593.1900
4 1.31271 523.0 686.8520
5 1.40512 458.0 735.2066
6 1.50402 416.0 820.1590
7 1.60989 377.0 912.7970
8 1.72321 355.0 1059.7630
9 1.84451 288.0 1041.7950
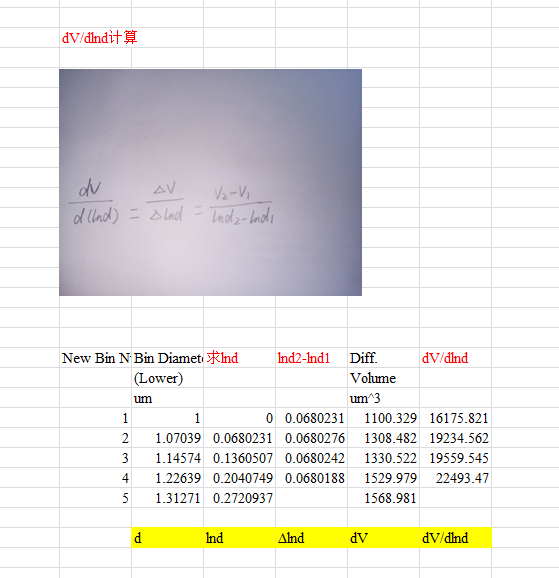
嗯,数据对的,至此通道合并完成。接下来模拟对数正太分别图,我们先看看公式
这里是朋友给的坐标求解方法
其实按公式计算最后拟合结果也是正确的,比这个手动计算微分简单的多,后面我会讲解两种方式拟合
首先我们采用第一种方式:即求得dV/dlnd,这个是y值,x值即为通道合并好的BD的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def draw(df):
# 计算lnd,即对BD列所有的数据应用logBD函数(此函数返回BD列数据以e为底的对数值)
lnBD = df.BD.apply(logBD)
# 计算Δlnd
lndList = []
for x in range(0, len(lnBD) - 1):
y = x + 1
tempNumb = lnBD[y] - lnBD[x]
lndList.append(tempNumb)
lndList.append(lndList[0])
# print df['VOL'].values
# 计算ΔdV / Δlnd
they = df['VOL'].values / lndList
thex = df['BD'].values
#画图
pl.scatter(thex, they)
plt.show()
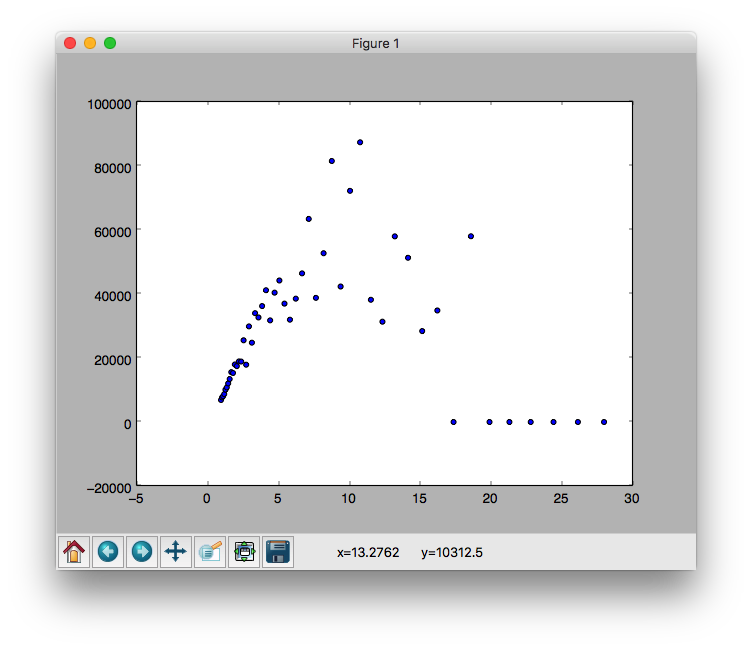
计算出x、y的值后,我们绘制出散点图看看是什么形状
接下来我们采用第二种方式来计算:根据上面的公式来求x,y值,看看有什么差别。首先我们得先求出公式里所需要的标准差跟期望值,然后带入函数求y值
1
2
3
#这里求标准差跟期望值是根据合并后BinDiameter的值来进行计算的
mean = df['BD'].mean()#期望值
std = df['BD'].std()#标准差
我们定义上面的对数正太分布函数
1
2
3
4
5
6
#正态分布函数
def normfun(x,y,mu,sigma):
#x为d,y为Vtotal,mu为BinDiameter的期望值,sigma为BinDiameter的方差
pdf = np.exp((((np.log(x) - np.log(mu))/np.log(sigma)) **2) * (-1/2))
a = y/(np.log(sigma) * np.sqrt(2*np.pi))
return pdf * a
求出y值后我们再次绘制下散点图
结果分布趋势相同
最后根据点进行图像拟合存储图片